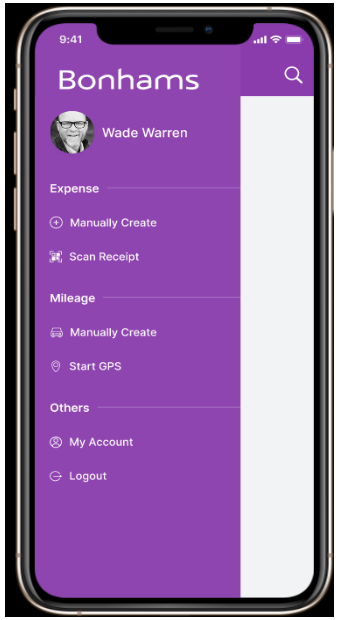
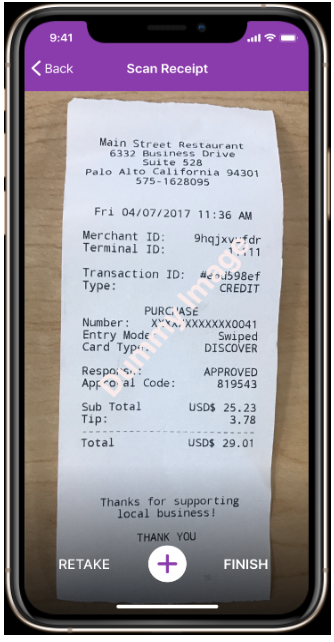
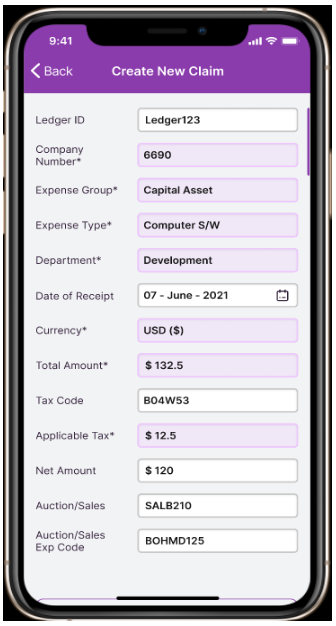
One of India's reputed auction companies approached ValueCoders to develop a flawless OCR mobile application to let users access digital data that can be shared and edited easily. The project is to develop an OCR Mobile Application to make it easier for people to convert printed or handwritten documents into a machine-readable format. It will give them quick access to digital data, which they can share and edit. The goal is also to implement post-correction algorithms that improve the accuracy when converting scanned images back into text characters.
The objective is to develop an OCR Mobile Application to ease the conversion of printed or handwritten documents into a machine-readable format. Manual entry of receipts acts as a bottleneck in the supply chain and leads to unnecessary issues.
As an innovative solution provider, ValueCoders aims to leverage technology to deliver an optimal OCR platform with the combination of hardware and software to convert printed or handwritten documents (not pdf) into a machine-readable, structured format. This conversion will be used to understand text embedded in images.
This machine learning technology can digitize receipts via scanner APIs and SDKs. The software intelligently scans and processes extracted data from receipts. Receipt OCR is an efficient way to analyze and store data.
It will provide users with easily accessible digital data that can be shared and edited. OCR post-correction algorithm is also implemented to improve the robustness of OCR-based systems against images.
Collaborating with ValueCoders, the client expected a highly accurate deep learning text detector to detect text in natural scene images. The app can detect and extract text within an image with support for many languages.
ValueCoders applied the technology with which, after detecting the text regions, they can extract each of the text Regions of Interest (ROIs) and pass them into Google Vision, enabling users to build a below-mentioned OCR pipeline.
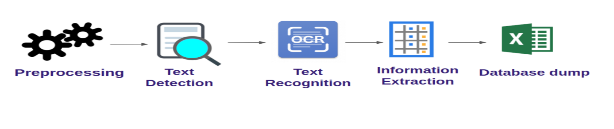
The most indispensable part of this project is to have easy access to advanced and adaptive OCR systems where users can scan receipts (text images) and split the amount. They will fetch the desired data in the predefined fields after the scan. Users could upload multiple images and scan them.
ValueCoders aimed to develop a system with a highly accurate deep learning text detector to detect receipts in different formats. Data fetch for the receipts with different templates of different currencies is the main requirement.
Most existing OCR-based systems are adversary-agnostic models, in which humans can not alter the extracted text from an image before the classification. But there is a need that correction can be done manually too.
| Problem Statement | How We Resolved |
|---|---|
| Receipt digitization since receipts have a lot of variations and are sometimes of low quality (noisy and blur). Scanning receipts also introduces several artifacts into our digital copy. These artifacts pose many readability challenges. | Here we used google vision API as it has an inbuilt AI method for data extraction. For this, we need to send noise-free images to Vision API in bytecode as all images are a set of numbers arranged in an N-dimensional array, i.e. (RG,B) in channels. We have used Opencv2 for image processing and conversion to the grayscale images to define the regions in black and white and then try to read data using the Google API vision library. |
| Accurate data fetching as per the different receipt formats and currency symbols of different countries. | Major currency list is made and mapping is done for major currencies with the help of LDML(Unicode Data Markup Language) |
| Correction or alteration of the text after capturing the image and filling data where it is missing in the extracted fields. | ValueCoders made a platform with an OCR post-correction algorithm to improve the robustness of OCR-based systems against images with perturbed embedded texts. This model will provide an option to enter data manually if fields are not captured correctly or missing in the extracted data. |
| OCR text works with printed text only and not with handwritten text. | ValueCoders implemented Machine Learning OCR using AI technology to capture handwritten text to a certain extent. |
Classifying images with embedded text using OCR systems involves three steps: text localization (detection), text recognition, and text classification. Users have to provide camera access permissions.
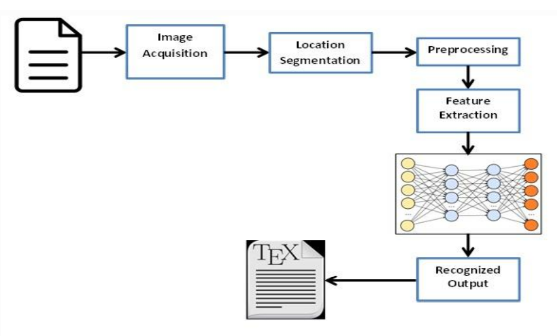
ValueCoders had developed the data extraction and data processing algorithm. It is a technology that recognizes text within a digital image. The image is scanned from the frontend and then sent to flask API, and the backend processes the data, manipulates data, and sends the output as JSON. We have used regular expressions to read currency if there is a currency symbol; else we have mapped major currency for extracting the currency.
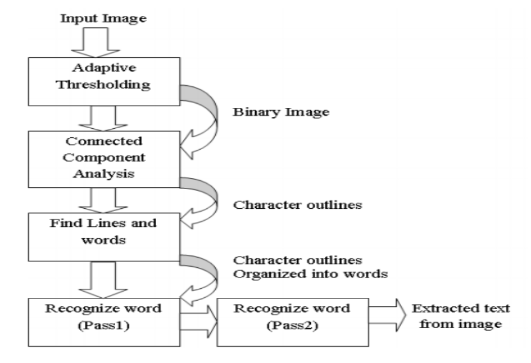
The architecture design document describes the components and specifications required to support the solution and ensure that the specific business and technical requirements are satisfied. This part of the document states the business goals and solution goals. Image is captured and goes through the preprocessor phase and, with the help of Google Vision API and OpenCV, is captured in predefined text fields.